크롤링하기 위해 필요한 라이브러리
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC안양 청년 정책 웹 사이트 url을 얻어온다.
driver.get("https://www.anyang.go.kr/youth/contents.do?key=3567")웹페이지에서 요소를 찾기 위해 암묵적으로 10초 대기
driver.implicitly_wait(10)제목, URL 크롤링
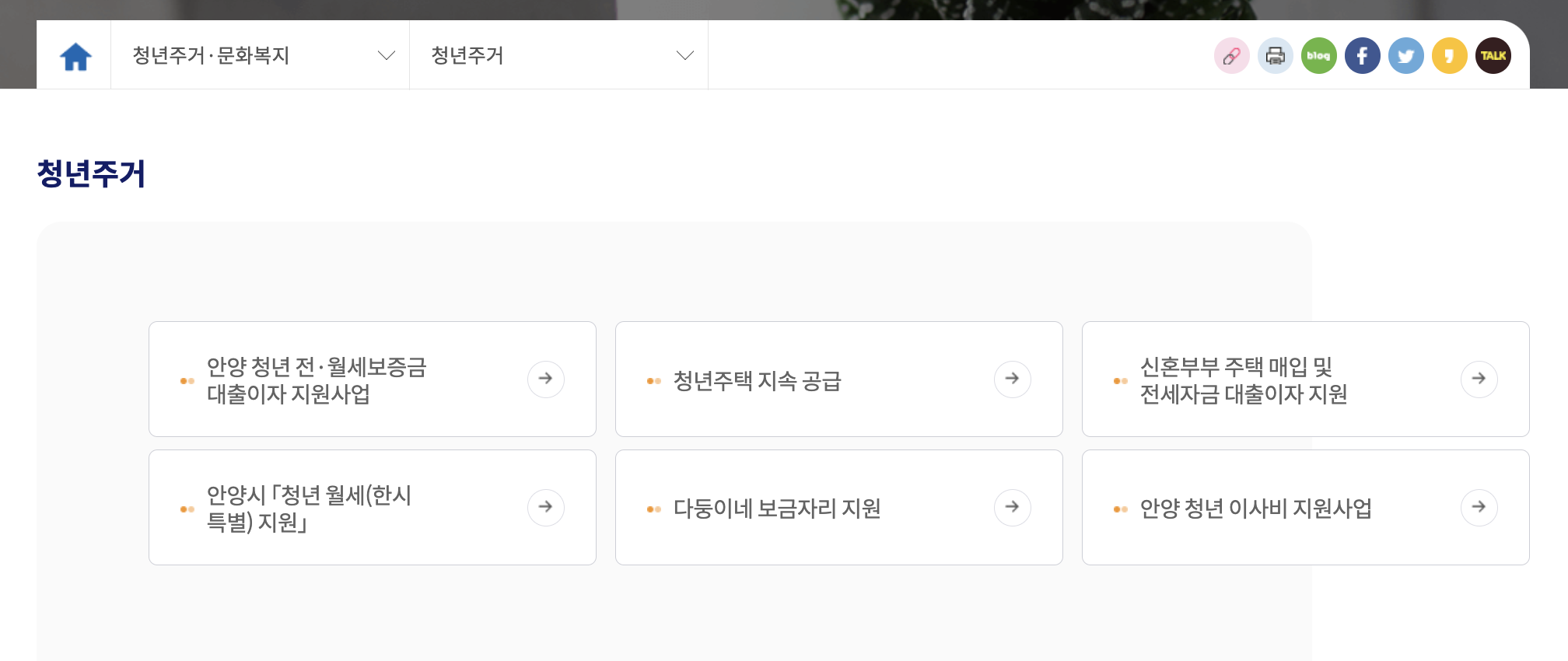
해당 정책이 몇 개인지 고정되어있지 않기 때문에 값을 설정할 수 없어서 while문을 사용하여 정책 요소들을 순회한다.
순회하면서 해당 정책의 각 url의 key값, 정책 제목을 구한다.
구해온 리스트 안의 딕셔너리 형태로 저장한다. key: key, title: 정책 제목 형태
while True:
try:
# key
url_element = driver.find_element(By.XPATH, '//*[@id="contents"]/div/div/div/ul/li[{}]/a'.format(i))
title = driver.find_element(By.XPATH, '//*[@id="contents"]/div/div/div/ul/li[{}]/a/span[1]'.format(i))
url = url_element.get_attribute('href')
key = url.split('=')[-1]
policyData.append({"key": key, "title": title.text})
i += 1
except NoSuchElementException:
break # 에러가 발생하면 반복문 종료
데이터프레임으로 저장
이후 고유한 값은 해당 url의 key 값으로 지정하고, 정책 제목은 title로 지정하여 데이터 프레임으로 만든다.
데이터 프레임은 엑셀의 파이썬 버전이라고 생각하면 쉽다.
dfPolicy = pd.DataFrame(policyData) # 데이터 프레임으로 만들기
위 리스트와 같은 값이지만 데이터프레임으로 저장하면 데이터를 관리하기 쉬워진다.
데이터프레임 column 추가하기
현재 key, title만 설정되어있다. sub_title, img의 값들도 추가할 것이기 때문이기 때문에 컬럼명부터 설정한다.
dfPolicy['sub_title'] = None
dfPolicy['img'] = None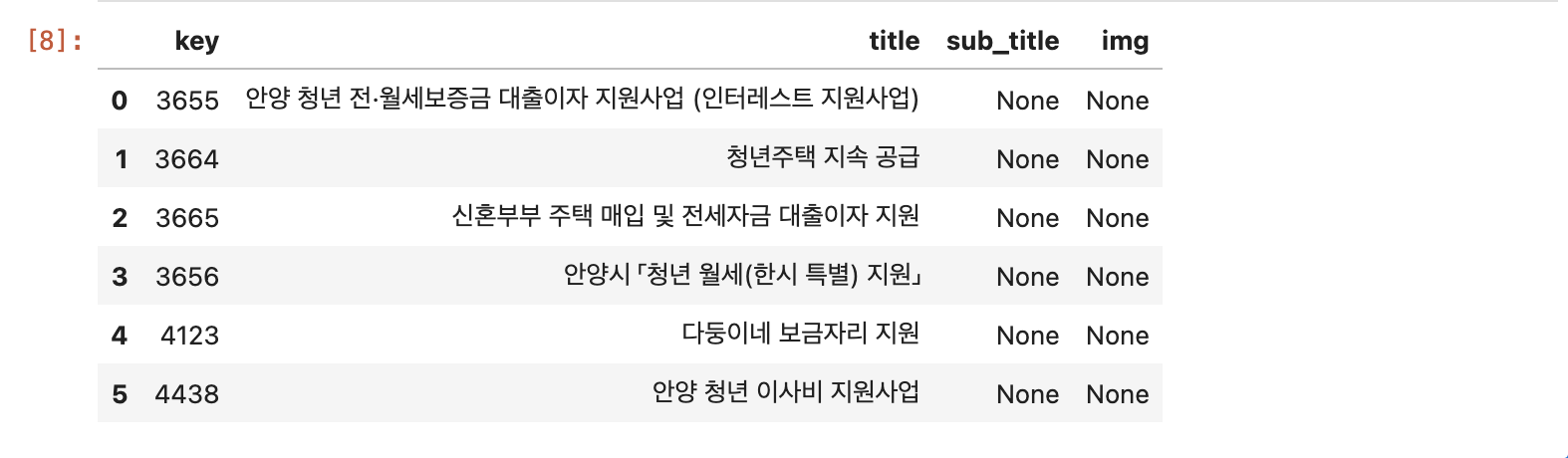
위에서 구한 Key 값으로 나머지 sub_title / img 구하기
url의 key 값으로 정책의 이미지와 사업 목적을 구해올 것이다.
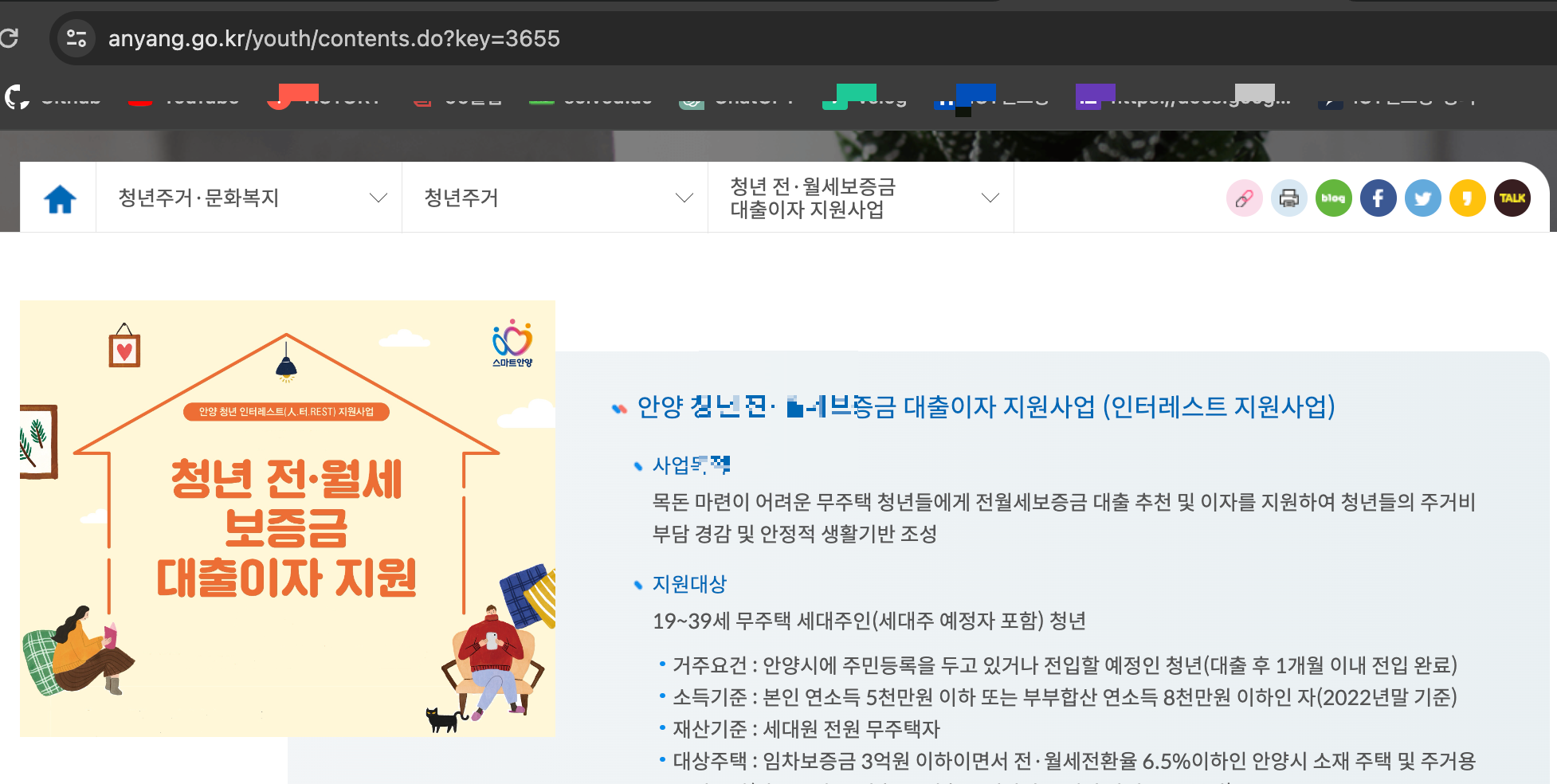
정책 페이지 순회
먼저 데이터 프레임 안에 있는 키값을 이용하여 정책 페이지를 순회한다
for index, row in dfPolicy.iterrows():
policy_key = row['key']
driver.get('https://www.anyang.go.kr/youth/contents.do?key={}'.format(policy_key))이미지 구하기
이미지는 로딩이 느릴 수도 있으므로 로드될 때까지 기다린 후 로딩이 끝나면 요소를 구해온 후 리스트로 저장
# 이미지 로드될 때까지 기다림
element = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, '//*[@id="contents"]/div/div/div[1]/div/div[1]/div/div/div/div/div/img')))
img = element.get_attribute('src')
policy_img_lst.append(img)사업목적 구하기
이후 사업목적도 동일한 방식으로 구해온 후 리스트로 저장
sub_title = driver.find_element(By.XPATH, '//*[@id="contents"]/div/div/div[2]/div/ul/li[1]/p')
sub_title_lst.append(sub_title.text)데이터 프레임에 저장
dfPolicy['img'] = policy_img_lst
dfPolicy['sub_title'] = sub_title_lst리스트 안의 값들을 데이터프레임 img, sub_title 열 안에 저장한다.

여러 줄로 잘렸지마나 데이터프레임에 key, title, sub_title, img가 잘 들어가있는 것을 볼 수 있다!
'졸업작품' 카테고리의 다른 글
| Pandas 데이터 MySQL - Node.JS 연결 (0) | 2024.04.21 |
|---|---|
| [Crowling] 크롤링한 데이터 엑셀 파일로 저장 (0) | 2024.03.18 |
| [Crowling] python 웹 크롤링 (0) | 2024.03.17 |
| [Spring] 스프링 공공데이터 API 활용하기(1) - 데이터 받아오기 (1) | 2024.03.16 |