전 포스팅에서 공공데이터 API를 활용하여 정책들을 받아왔었다.
그거 하는 것도 꽤나 애먹었는데 내가 필요한 정보들이 아니었다.
그래서 여러 사이트를 검색해보던 중 청년 정책들을 잘 소개해주는 사이트를 발견했다.
카테고리 주거분야로 들어가면 주거 관련 정책들만 쫙 모아주니 여기서 데이터를 받아오면 좋겠다 생각했다.
그래서 이번에는 웹 크롤링을 시도해봤다. 이것저것 정말 많이 해보는 ... (vsCode 사용했습니다.)
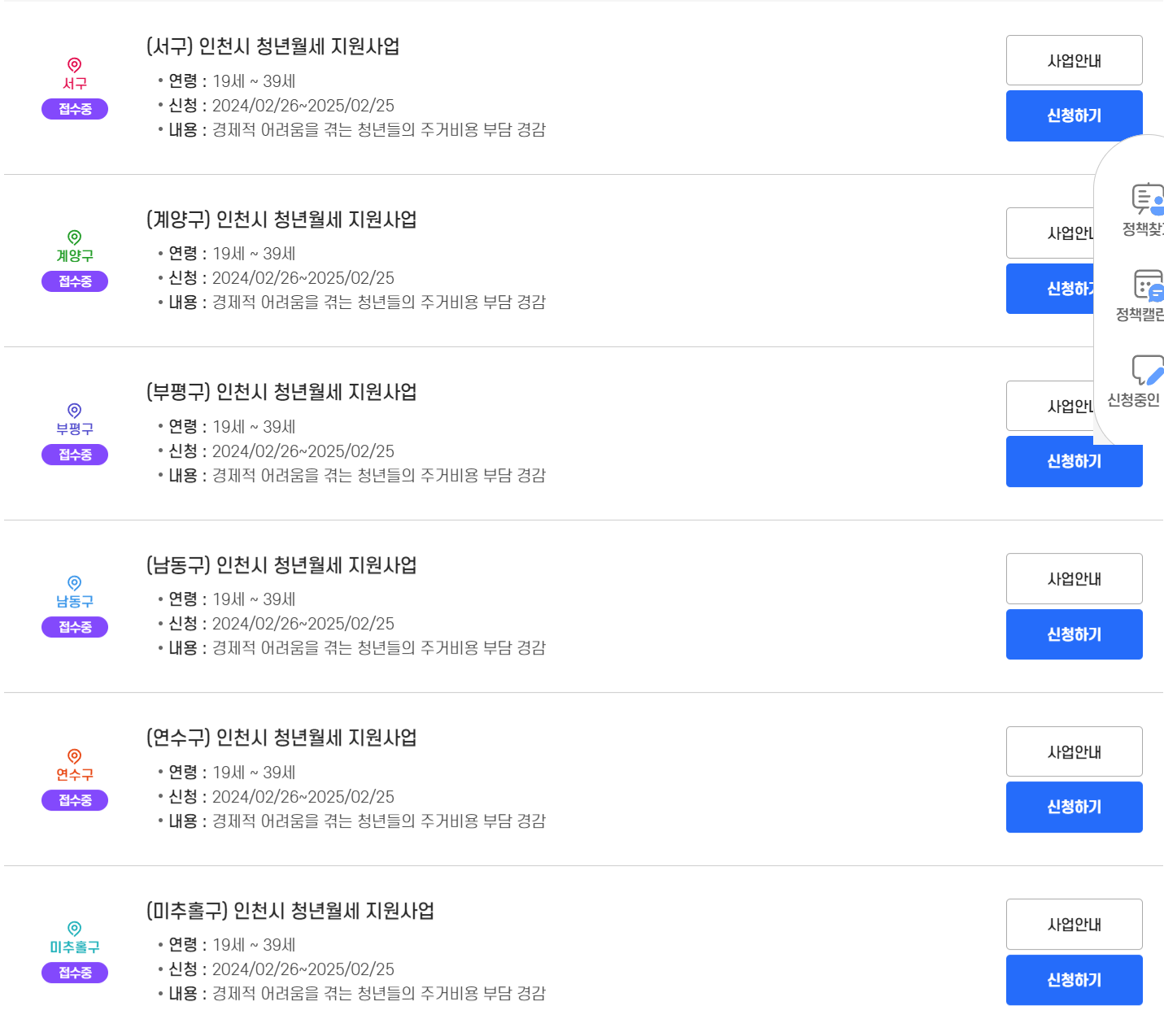
내가 할 것은
1. 위의 사이트에서 정책 제목들을 가져오는 것
2. 해당 정책의 상세보기에 접근할 수 있는 '사업 안내' 버튼 URL을 가져오는 것
1. 필요한 라이브러리 설치
크롤링에 기본이 되는 라이브러리들이다.
- pip install requests
- pip install beautifulsoup
파이썬 버전 문제때문에 시간을 또 잡아먹었는데
https://youtu.be/eJ7kqK18afY?si=cD5xM1nliGlPtFhW
이거보고 해결함 ㅠㅠ
2. 크롤링하고 싶은 URL 가져오기
# 크롤링 기본
import requests
from bs4 import BeautifulSoup
# 크롤링하고 싶은 url get해오기
response = requests.get("https://youth.incheon.go.kr/youthpolicy/youthPolicyInfoList.do?")
html = response.text # html 전체 코드 들어있음.
soup = BeautifulSoup(html, 'html.parser') # html 번역기
# soup.select > 여러개 / soup.select_one > 한 개 선택
titles = soup.select(".tit")
for title in titles:
print(title.text.strip())
설치한 라이브러리들을 import 해준다.
requests.get("URL")로 내가 크롤링하고 싶은 주소를 넣는다.
성공적으로 가져와졌다면 response 출력시 <Response [200]> 이 뜰 것이다.
이후 html번역기인 html.parser를 활용
soup.select() < css 선택자를 활용하여 가져오고 싶은 태그 선택
- select > 한 개 선택
- select_one > 여러 개 선택
.tit가 여러 개라면 리스트 형태로 titles에 들어온다.
반복문으로 title를 출력

성공 나이쓰 !
3. 링크 가져오기
import requests
from bs4 import BeautifulSoup
response = requests.get("https://youth.incheon.go.kr/youthpolicy/youthPolicyInfoList.do?menudiv=dwelling")
html = response.text
soup = BeautifulSoup(html, 'html.parser')
titles = soup.select(".boardList .con-box .tit") # 정책 title
links = soup.select(".boardList .btn-box .btn:first-child") # 해당 정책 URL 접근
for link in links:
url = link.attrs['href']
print(f'https://youth.incheon.go.kr{url}')위와 비슷한 코드이다.
다른 은 a태그 href 속성을 활용하여 url을 가져온 것
link에는 a 태그가 들어가 있다.
link.attrs['href'] : 해당 링크의 url을 가져올 수 있다.
위의 '~ 인천시 청년월세 지원사업' 들의 해당 정책 상세보기 링크에 접근할 수 있는 것!
4. 여러 페이지 가져오기
정책들이 여러 페이지로 이루어져 있을 것이다.
페이지를 이동할 때마다 변경되는 url을 보고 활용하면 된다.


페이지가 이동될 때 pgno= 1, 2로 변경되는 것을 볼 수 있다.
# 여러 페이지 가져오기
import requests
from bs4 import BeautifulSoup
pageNum = 1
for i in range(1, 10):
print(f'{pageNum}페이지입니다.')
response = requests.get(f'https://youth.incheon.go.kr/youthpolicy/youthPolicyInfoList.do?menudiv=dwelling&pgno={i}')
html = response.text
soup = BeautifulSoup(html, 'html.parser')
titles = soup.select(".boardList .con-box .tit") # 정책 title
for title in titles:
print(title.text.strip())
pageNum += 1
반복문으로 pgno={i} < 1~10페이지까지의 모든 정책 제목을 가져올 수 있었다.
간단하게 사이트 크롤링해보기 성공
앞으로의 여정은 멀고도 험하지만요 시작이 반이라고~
'기타' 카테고리의 다른 글
| 크롤링한 데이터 Pandas로 관리 (0) | 2024.04.21 |
|---|---|
| [Crowling] 크롤링한 데이터 엑셀 파일로 저장 (0) | 2024.03.18 |
| [Spring] 스프링 공공데이터 API 활용하기(1) - 데이터 받아오기 (1) | 2024.03.16 |


